El momento es una aproximación de promediado que provee estabilidad
cuando se alcanzan los pesos óptimos en el aprendizaje. Este método toma en
cuenta el promedio de los cambios pasados (en los pesos) en el incremento de
peso, suavizando el cambio neto de peso. La idea es usar el promedio
exponencial de todos los cambios de peso previos para guiar el cambio
actual. La expresión matemática de
cambio de peso para cada peso es:

Código del programa
%ACTIVIDAD 12
clear all
in0=1;
in1=[0 1 0 1];
in2=[0 0 1 1];
targ=[0.1 0.9 0.9 0.1];
w1=(1-2*rand)*0.5;
w2=(1-2*rand)*0.5;
w3=(1-2*rand)*0.5;
w4=(1-2*rand)*0.5;
w5=(1-2*rand)*0.5;
w6=(1-2*rand)*0.5;
w7=(1-2*rand)*0.5;
w8=(1-2*rand)*0.5;
w9=(1-2*rand)*0.5;
n=5;
alpha=4;
u=0.95;
offset=0.9;
%acumuladores
ADW1=0;ADW2=0;ADW3=0;ADW4=0;ADW5=0;ADW6=0;
ADW7=0;ADW8=0;ADW9=0;
ADW1_ant=0;ADW2_ant=0;ADW3_ant=0;ADW4_ant=0;ADW5_ant=0;ADW6_ant=0;
ADW7_ant=0;ADW8_ant=0;ADW9_ant=0;
for j=1:1000
err_total=0;
for i=1:4
net1 = in1(i)*w1+in2(i)*w3+in0*w7;
net2 = in2(i)*w4+in1(i)*w2+in0*w8;
out1 = 1/(1+exp(-alpha*net1));
out2 = 1/(1+exp(-alpha*net2));
net = out1*w5+out2*w6+in0*w9;
out = 1/(1+exp(-alpha*net));
%VARIACIONES DE LOS PESOS CON CADA PATRON DE
ENTRENAMIENTO
D_W1=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*w5*[alpha*out1*(1-out1)+
offset]*in1(i);
D_W2=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*w6*[alpha*out2*(1-out2)+
offset]*in1(i);
D_W3=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*w5*[alpha*out1*(1-out1)+
offset]*in2(i);
D_W4=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*w6*[alpha*out2*(1-out2)+
offset]*in2(i);
D_W5= n*(targ(i)-out)*[alpha*out*(1-out)+
offset]*out1;
D_W6=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*out2;
D_W7=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*w5*[alpha*out1*(1-out1)+ offset]*1;
D_W8=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset]*w6*[alpha*out2*(1-out2)+ offset]*1;
D_W9=
n*(targ(i)-out)*[alpha*out*(1-out)+ offset];
err_parc=(targ(i)-out)^2;
err_total= err_total+err_parc;
ADW1= ADW1+D_W1;
ADW2= ADW2+D_W2;
ADW3= ADW3+D_W3;
ADW4= ADW4+D_W4;
ADW5= ADW5+D_W5;
ADW6= ADW6+D_W6;
ADW7= ADW7+D_W7;
ADW8= ADW8+D_W8;
ADW9= ADW9+D_W9;
end
%ESTE ES EL AW DEL METODO MOMENTO
w1=w1+u*ADW1_ant+(1-u)*ADW1;
w2=w2+u*ADW2_ant+(1-u)*ADW2;
w3=w3+u*ADW3_ant+(1-u)*ADW3;
w4=w4+u*ADW4_ant+(1-u)*ADW4;
w5=w5+u*ADW5_ant+(1-u)*ADW5;
w6=w6+u*ADW6_ant+(1-u)*ADW6;
w7=w7+u*ADW7_ant+(1-u)*ADW7;
w8=w8+u*ADW8_ant+(1-u)*ADW8;
w9=w9+u*ADW9_ant+(1-u)*ADW9;
ADW1_ant=u*ADW1_ant+(1-u)*ADW1;
ADW2_ant=u*ADW2_ant+(1-u)*ADW2;
ADW3_ant=u*ADW3_ant+(1-u)*ADW3;
ADW4_ant=u*ADW4_ant+(1-u)*ADW4;
ADW5_ant=u*ADW5_ant+(1-u)*ADW5;
ADW6_ant=u*ADW6_ant+(1-u)*ADW6;
ADW7_ant=u*ADW7_ant+(1-u)*ADW7;
ADW8_ant=u*ADW8_ant+(1-u)*ADW8;
ADW9_ant=u*ADW9_ant+(1-u)*ADW9;
ADW1=0;
ADW2=0;
ADW3=0;
ADW4=0;
ADW5=0;
ADW6=0;
ADW7=0;
ADW8=0;
ADW9=0;
vector_epocas(j)=j;
vector_errores(j)=err_total;
mensaje=sprintf('Aprendisaje: %2.3f u=%2.3f ',n,u);
w11=w1;
w12=w2;
w21=w3;
w22=w4;
lw1=w5;
lw2=w6;
b1=w7;
b2=w8;
b3=w9;
[x,y] = meshgrid(0:.01:1,0:.01:1);
alpha=4;
net1 = x*w11+y*w21+in0.*b1;
net2 = x*w12+y*w22+in0*b2;
out1=1./(1+exp(-alpha*net1));
out2=1./(1+exp(-alpha*net2));
net = out1*lw1+out2*lw2+in0*b3;
out=1./(1+exp(-alpha*net));
out_frontera=round(out);
subplot(3,1,1);
plot(vector_epocas,vector_errores);
title(mensaje);
subplot(3,1,2);
mesh(x,y,out);
subplot(3,1,3);
mesh(x,y,out_frontera);
pause(0.01);
end
Resultados
- . Resultados para (factor de aprendizaje, momento) de a) (0.2 0.01); b (0.2 0.5);c) (0.2 0.9)

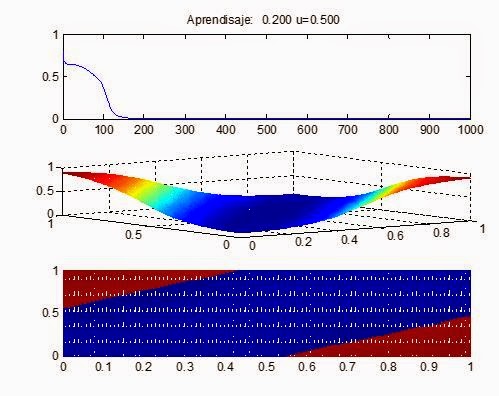

2 2. Resultados para (factor de aprendizaje, momento) de a) (5
0.01); b)(5 0.5); c)









0 comentarios :
Publicar un comentario